




If you're among the elite subset of sales development leaders who know how to operate a precise outbound motion, you already know that sales call disposition are direction. They tell you what happens next to the prospect, not just what already happened.
But if you're doing it right, dispositions are also diagnosis. They can tell you exactly what's causing poor performance in every outbound sales campaign you ever run.
There are exactly four variables that determine whether a cold calling campaign produces pipeline: your list, your message, your rep execution, and your follow-up strategy. Every underperforming campaign traces back to one or more of those four. No exceptions.
Good dispositioning lets you pinpoint which one of those four things is the active constraint at any given time. Bad list targeting shows up as high wrong-person rates. Weak messaging shows up as low activation despite adequate connect rates. Rep execution problems show up as elevated not-interested rates against a list you know is right. Follow-up failures show up as a not-now bucket that never gets actioned.
And there are dozens of disposition patterns - the proportion of one distribution to the others - that can tell you even more about your campaigns, and help you decide what to test next.
This article assumes you already have your dispositions defined and your reps trained to apply them consistently. If you haven't done that work yet, start with our foundational guide to sales call dispositions. What follows is about reading the data — and knowing what to change when it tells you something is wrong.
Three Causes of Useless Disposition Data
Most cold call disposition setups fail in one of three ways.
- The binary trap. Everything that isn't a meeting gets swept into a catch-all bucket. This happens when the distinction between non "meeting set" dispositions is meaningless, unclear, or not adhered to by your reps. As a result, you know the outcome was not a meeting for that portion of your cold calls, but you'll know nothing about the cause.
- Too many dispositions and/or inconsistent usage. The data exists but can't be read. If your reps are describing the same situation with different disposition buckets, your analysis will lead to conclusions that don't actually exist. Which means your data is worthless. Usually happens because there are unclear or just too many disposition buckets to choose from.
- Imprecise definitions. Dispositions that exist on paper but mean different things to different reps. "Not interested" is the classic offender — one rep uses it for a polite decline, another for a hang-up, another for an explicit vendor objection. So in the report, you just get one bucket that holds a variety of different (and now invisible) signals. So there's zero diagnostic value there.
The Six Cold Call Dispositions Every B2B Sales Dev Team Should Use
- Meeting Scheduled. A confirmed calendar event. This is your most obvious win, but also the least diagnostic disposition.
- Activated. The prospect showed Interest, Intrigue, or Intent without booking. They reached toward the conversation. This is your leading indicator of pipeline quality.
- Not Now. Right person, right account, wrong moment, shared with a specific, real reason. Locked budget cycle, active vendor contract, frozen purchasing. This is not a polite brush-off. It should be a calendar reminder for the rep with a contact name attached.
- Not Me. Wrong contact, and you left without knowing who the right one is. You're back to the list.
- Referred. Wrong contact, but they told you who the right one is. You leave with at least a name and an implicit warm introduction.
- Not Interested. The call ended with your prospect hearing your pitch, but responding that it didn't resonate with them. No timing problem, no referral to a better contact, no interest, intrigue or intent (activation).
Bonus: We've recently started using an "Intel" disposition to denote when there's other valuable intel we've gathered that we should use to inform our next step. For example, if we didn't get the right contact, a referral to the right one, any information about timing, but we did learn that our prospect's sales team has 24 reps, or they only cold-call in the first week of every month, or 80% of their pipeline comes from cold calls...
That's valuable intel. Having the call marked this way makes it easy for automated workflows and LLMs to pull the data from the call transcript and use it to generate account intelligence reports.
The Order of Operations for Proper Pipeline Diagnosis
After a chunk of cold calls, you'll have a data set with a distribution of dispositions. To make meaning from that data, you need to read the distribution in sequence. Some variables contaminate the signals used to diagnose others. For example, evaluating your message before confirming your targeting is right would mean you're analyzing performance against a population that includes people who were never eligible to respond to your offer regardless of what was said.
So here's what to think about and in what order. I've excluded follow-up from this list for now because the first pass at distribution reporting is really focused on diagnosing issues in the first three pillars: your list, your message, and your reps' execution.
Step 1: Targeting
Look at the percentage of your cold calls that resulted in Not Me and Referred before anything else. If the sum of those two disposition buckets is too high, you've got targeting issues.
General guidelines:
- Below 25%: Your targeting is well-calibrated. Move to message.
- 25–40%: Meaningful targeting issue. Worth correcting in the next iteration, but other signals still have enough clean data to read.
- Above 40%: Stop. You have a population problem. Diagnosing message or rep execution against this list will produce conclusions that don't mean anything. Fix targeting first.
The logic here is obviously that if most of your completed conversations are with people who can't act on your offer, no amount of messaging refinement changes the outcome.
Step 2: Message
With targeting confirmed, look at the relationship between activation rate and meeting rate, not either one in isolation.
Assuming the list is good, a message that works should produce both activations and meetings-set. Meetings from prospects ready to commit. Activation from prospects who engaged genuinely but weren't ready to book.
Two of the most common signs that your messaging needs work:
- Decent meetings, near-zero activation. The pitch is closing hard without landing well. Prospects are saying yes before they've engaged with the substance of what you're offering. These meetings cancel more, open cold, and convert poorly. A 10% meeting rate and a 3% activation rate is fragile.
- Low activation and low meetings. The message isn't generating engagement or bookings. Nothing is sticking when you reach the right person. This requires testing at the structural level. You need to look at how you're framing the problems you address, how you position the offer, the moment in the pitch where the conversation is designed to turn, how you close.
Quick note: those could both still be rep performance issues. If you see these patterns these are hypotheses to test, not true diagnoses.
Step 3: Rep
If targeting and message both confirm but Not Interested remains elevated, rep execution is the last area to look at.
People are people, and as much as we all try to make every rep exactly like our best rep, the reality is that issues with your reps are executing don't show up uniformly in campaign-level data. Instead, they show up as variance between individual reps, and campaign-level metrics average that out. Always segment Not Interested by rep before drawing a conclusion about the message.
Could be one rep is dragging down your average. Or one rep is making your message look great when it's not.
Look for:
Uniformity. Are all reps logging calls Not Interested at similarly elevated rates? This points at the script or the angle, not execution.
Concentration. There's one or two reps logging Not Interested more often than others. This presents a coaching opportunity, not a campaign problem. Do not conflate the two. It's expensive to throw out a script that works for most of your team to fix what is actually an execution issue.
What the Team-Wide Distribution Alone Cannot Tell You
Three things fall outside what the distribution can confirm on its own.
First, the distribution of your disposition buckets cannot tell you if you're not getting enough connects in the first place. If your connect rate sucks (industry average is 3-5%, which is actually horrible), you've got problems. You aren't getting enough dispositions in the first place AND you won't be able to see that as a cause of campaign underperformance in the pie-chart breakdown of your dispositions.
Second, it won't tell you whether elevated Not Interested against a clean list reflects a message problem or a rep problem. The distribution narrows the hypothesis. Segmenting by rep narrows it further. Call review can make your hypothesis look smarter, but the only real way to confirm this is definitely your diagnosis is to improve, test, and re-measure.
You also can't tell which specific rep is responsible. A campaign-level Not Interested rate of 40% might be four reps at 38-44%, which would mean you have a clear a message problem, or one rep at 60% and three at 33%, which is clearly a coaching problem that's dragging your average down. The aggregate rate cannot distinguish between those two situations.
How to Read Common Disposition Distribution Patterns
By the way, if you'd rather see this lesson as a video, I did a 14 minute version on TitanTV called Disposition Science.
Tons of other in-depth sales math lessons in there, too.
High Not Me and Referred Combined: Your List Is Wrong
When Not Me and Referred together account for a large share of completions, your hypothesis should be that the personas on your list are wrong. Not the accounts, necessarily, but the people.
The accounts may be exactly right. But what you're seeing is that the titles on your list don't own the problem you're solving. When that's the case, look into your Referred bucket. Those referral destinations are your corrected persona. If 80% of the people sending you away are directing you to the same function or title, your next list build should weight heavily toward that title. The campaign already ran the research for you.
Low Activated Alongside Decent Meetings: Messaging Is Forcing, Not Earning
If meetings are happening but activation is nearly absent, those meetings aren't being generated by genuine interest. They're being closed by pressure before the prospect has actually decided they want to engage.
These meetings cancel more often, open cold, and convert poorly. They are waste in your system. You do not want these meetings. Even though it looks bad because it's "not a meeting", activation is the leading indicator of pipeline quality. A good rate of actiated contacts should tell you whether the message is creating real interest with the right contacts, or just manufacturing calendar events. When activation is missing, test the message before you celebrate the meeting rate.
High Not Interested with Low Not Me: Execution or Angle Issues
Low Not Me means you're reaching the right people. High Not Interested means they're not engaging. The list isn't the problem, which means it must be ether your messaging or your reps.
Segment dispositions by rep. If the Not Interested rate is elevated and uniform across the team, the pitch is what's failing. They're all hitting the same wall because they're all delivering the same thing. When you go to call review, listen for where the conversation starts to break down, whether it's after the opener, after the problem framing, after the ask. Then fix that thing.
If the Not Interested rate is concentrated in one or two reps with others performing normally, the message is working. Go to call review and listen for departure from message for underperforming reps. They might compresses the setup, skip the framing, or push harder instead of pivoting when the prospect objects.
To add more depth of insight here, look at the activation rate by rep too.
Two reps with identical Not Interested rates can have completely different distributions. One with 16% activation and 10% meetings, another with 3% activation and 15% meetings. The second rep is closing aggressively without building real interest. Those metrics look strong until the meeting hold rate and downstream conversion tell a different story.
High Not Now: A Market Timing Signal
A high concentration of genuine Not Nows, with specific, real reasons. means the campaign is working in the wrong window. The targeting is correct, the message is landing, the timing isn't right.
This is not a signal to change the list or the message. It's a signal to build a re-engagement sequence, lean on follow-up and work with your marketing team to maintain contact over time. Teams that recycle connect data into targeted follow-up lists achieve connect rates of 26–32%.=
That bucket is future pipeline, almost like they referredthemselves. Never treat contacts in this bucket like they're dead and gone, just because they didn't book a meeting on your first connect.
How to Form and Test a Hypothesis
Once the distribution points you toward a variable, the only productive response is to change exactly one thing and measure the shift.
Change one variable. Run the next batch of completions. Look at whether the distribution moved in the direction you predicted. If Not Me and Referred came down and meetings went up, the list fix worked. If the distribution barely moved, the fix was right but incomplete. Keep it, change one more variable, and test again.
This is campaign optimization as A/B testing: form a hypothesis, make a single variable change, see the disposition outcome, make a verdict. Repeat until the distribution reflects what you want.
You don't need a complex dashboard to know if a change worked. Watch three things: Did the problematic buckets get smaller? Did the valuable ones get larger? Did the distribution move in the direction you predicted?
Better means your hypothesis was right. Worse means your intervention made things worse or you changed the wrong variable. That will happen because that's the nature of testing. When it does, just revert and form a new hypothesis. Just because you didn't get the outcome you wanted doesn't mean you got nothing. You learned what is NOT the problem.
Static means the change had no effect, which is another extremely valuable thing to know. You can rule out one cause and point toward a different variable, and avoid wasting time testing that thing again in the future.
A Real Example of How We Improved a Campaign with This Approach
The campaign opened with a call blitz through a list we scored with TitanX Phone Intent™. Our reps made 266 dials, got 69 connects, and had 42 completions. A 26% connect rate, roughly 60% of connects turning into full completions. By raw conversion metrics, that looks pretty good so far.
The disposition breakdown did show some issues, though. 10% Meeting Set, 3% Activation, 16% Not Now, 35% Not Me, 26% Referred, 10% Not Interested.
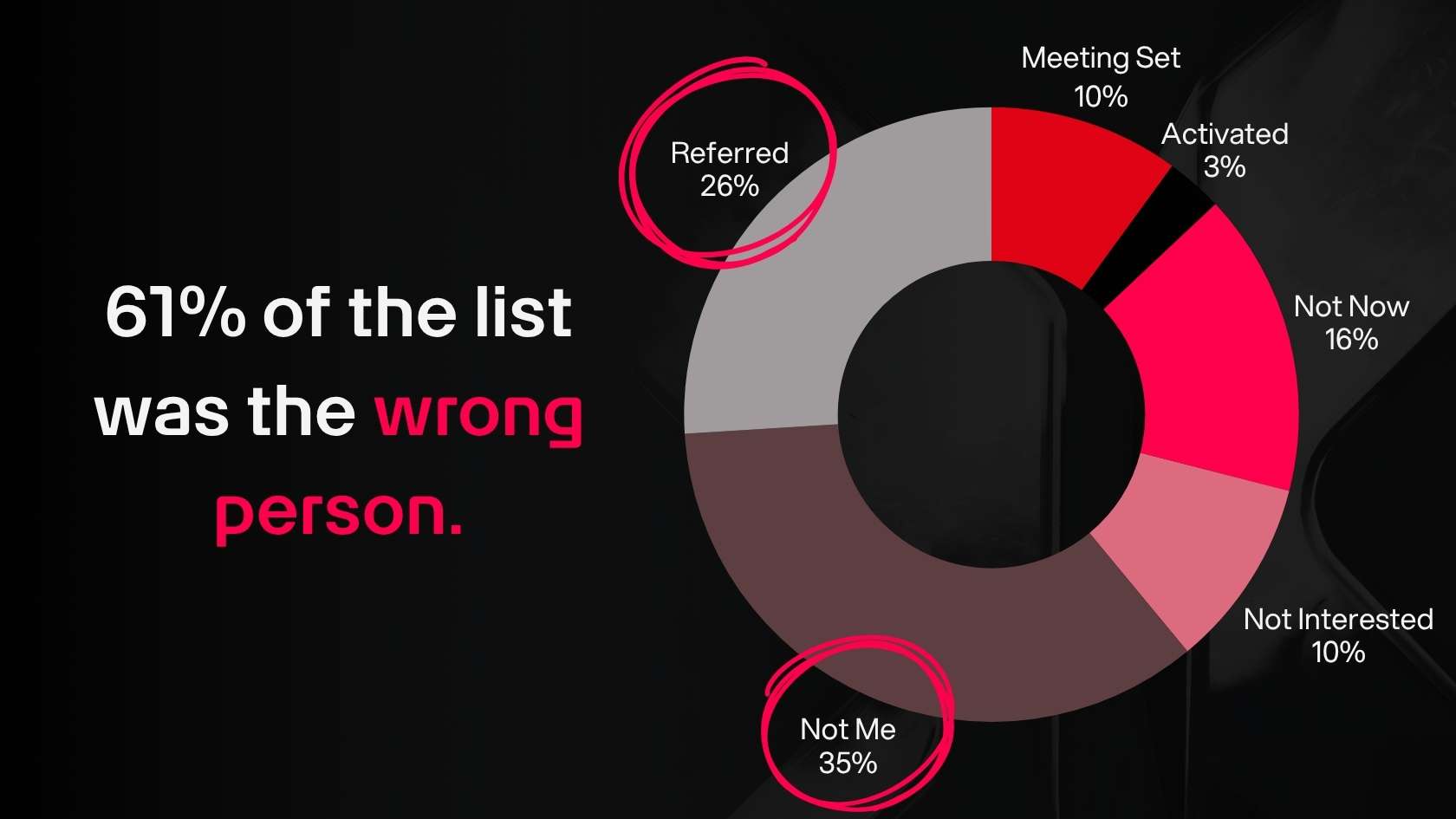
Combined, 61% of every completed call ended with confirmation that the person reached was not the person who should have been reached.
That number doesn't invite further interpretation. The personas were wrong. More than half of the completed conversations were with people who couldn't act on the offer, and many of them couldn't even point to the person who could.
The referral destinations from that first run became the primary titles on the second list. So our hypothesis is that the contacts are wrong, the accounts are right, and the referred list represents better personas for campaign 2. So title was the only variable we changed for our second round on this campaign.
.jpg)
After that one change, our meeting rate moved from 10% to 17%. Not Me dropped from 35% to 21%. Referred dropped from 26% to 16%. Not Interested fell to 1%. Not Now went up to 27%, and Activation moved from 3% to 18%. When the right people are on the list and the message is calibrated to their situation, conversations open up in a way they simply don't when you're dialing the wrong title.
From an activity standpoint: 266 dials became 333. Connect rate improved from 26% to 27%, producing 91 connects versus 69. Seven booked meetings instead of three. For a ~25% increase in activity, outcomes improved by 230%.
In both runs, we used our own Phone Intent™ scoring so reps know which contacts were most likely to answer before they started dialing. Because every dial gives a much greater chance of a conversation, we can run these tests and iterate quickly, and with greater efficiency.
What Disposition Data Alone Can't Tell You
Disposition analysis is a diagnostic for execution problems within a functioning cold calling program. It can tell you whether your list, your message, or your rep execution is the constrain, and it can tell you how to fix it through deliberate, single-variable testing.
It can't tell you who to call in the first place.
If your connect rates are chronically low, if your reps are spending the majority of their time reaching voicemail, or if the unit economics of your program require volume to compensate for bad conversion, disposition analysis will help you optimize around the edges.
It won't fix the underlying reachability problem. That's a different problem, upstream of the campaign, in how you're identifying which prospects are actually worth dialing and when.
Some campaigns need a new angle. Some need a tighter list or some good coaching to a rep who is impacting your averages. But some need to be rebuilt around a different premise: that not all dials are equal, that a small share of prospects on any list are dramatically more likely to pick up the phone, and that concentrating effort there changes the economics more than any disposition-level optimization can.
Lastly, one important boundary on the analysis itself: disposition data requires a minimum sample size of approximately 50 completions before the distribution is meaningful. Below that threshold, you should consider disposition distribution noise. Build toward that floor before setting your first hypothesis, and build subsequent test batches toward the same threshold before declaring whether a variable change worked.
This is precision outbound in action. It's the only viable path forward.
